
CVPR 2026
Direct Time-of-Flight (dToF) sensors provide highly accurate metric depth and are more robust than indirect ToF systems in challenging real-world conditions. However, their high manufacturing cost and limited photodiode array size produce depth maps that are extremely sparse, low-resolution, and noisy, making them unsuitable for VR/XR, robotics, and 3D perception tasks that require dense metric depth. Existing monocular and depth completion methods struggle to handle the unique sampling patterns and hardware artifacts of dToF devices, and their performance often deteriorates significantly under severe sparsity or noise. We present a generalizable framework for dense metric depth completion from sparse dToF measurements, capable of operating across diverse sensor types, sparsity levels, and noise conditions. Our model employs a depth-guided dual-branch Vision Transformer encoder that processes RGB images and sparse dToF measurements separately, while a masked joint attention module allows depth tokens to reliably guide image features without being overwritten by them. A lightweight decoder reconstructs dense metric depth efficiently, without diffusion-based or refinement-heavy post-processing. To address the scarcity of paired training data, we introduce a comprehensive dToF simulation pipeline that reproduces the characteristics of flash, sub-VGA flash, and rotating sensors, including hardware-induced degradation, irregular sparsity, and realistic noise distributions. Trained entirely on synthetic data, our model achieves strong zero-shot generalization across 6 datasets and 3 real dToF devices, outperforming state-of-the-art approaches in both accuracy and computational efficiency. This establishes a robust and practical solution for dense metric depth completion from sparse direct ToF sensors.
Pick a scene, then drag the two handles to reveal the RGB image, the sparse depth input, and our completed depth within a single frame.


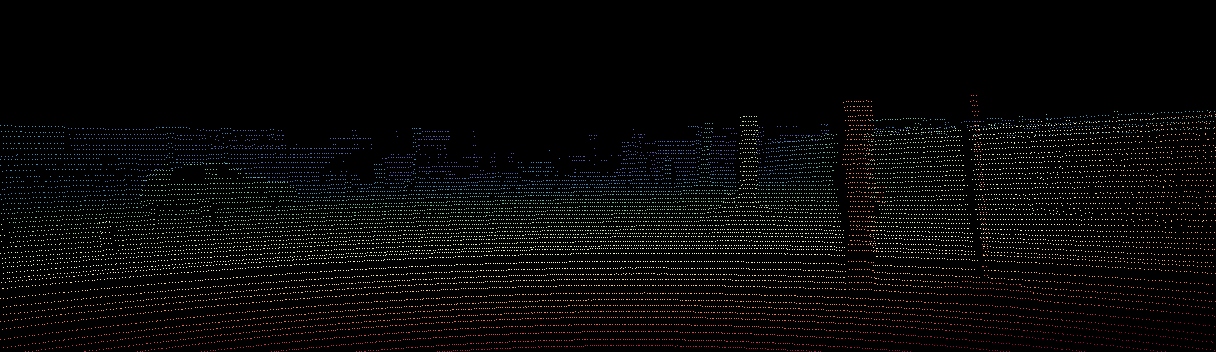
Interactive 3D point clouds. The sparse dToF input is shown alongside each method’s completed result — all views share one synced camera, so dragging to orbit (or scrolling to zoom) in any panel moves them all together.
Drag = rotate · Scroll = zoom · Right-drag = pan · all panels share one camera
@InProceedings{Kim_2026_CVPR,
author = {Hakyeong Kim and Ruicheng Wang and
Chengtang Yao and Jiaolong Yang and Min H. Kim},
title = {Dense Metric Depth Completion from Sparse Direct Time-of-Flight Sensors},
booktitle = {IEEE Conference on Computer Vision and
Pattern Recognition (CVPR)},
month = {June},
year = {2026}
}